
EL MODELO DE DATOS DE PANEL
EL MODELO DE DATOS DE PANEL
Por: Juan M. Gutierrez
La razon de uso de la tecnica econometrica de datos de panel aprovecha la informacion que provee la variabilidad transversal, la identificacion y estimacion de los parametros de una funcion de respuesta explotando la informacion de la variacion de las variables independientes incluidas en el modelo. Si las variables no presentan excesiva variabilidad temporal pero si transversal la aproximacion con datos de panel aportaria capacidad extra para esa estimacion. La forma funcional general es:
Donde:
- significa la -esima unidad transversal (pais, persona, etc.)
- el tiempo (ano, trimestre, mes, etc.)
Esta formulacion permite la combinacion de multiples parametros individuales y temporales.
Entre las muchas especificaciones tecnicas de los modelos de Datos de Panel los mas recurrentes son:
- El Modelo de "efectos fijos"
- El modelo de "efectos aleatorios"
La diferencia entre efectos fijos o aleatorios no radica en la morfologia del modelo, que es siempre la siguiente:
Es decir, en vez de considerar a como fija, suponemos que es una variable aleatoria con un valor medio y una desviacion aleatoria de este valor medio. Sustituyendo en obtenemos:
Donde:
- representa la heterogeneidad transversal inobservable.
Esta formulacion es una manera util de evitar que la inadvertida diferencia entre los individuos de la muestra tuviese que excluirse por omision, pero la omision de variables relevantes puede ocasionar que los estimadores esten sesgados y estos sean inconsistentes. Una modelizacion de datos de panel de efectos fijos unidireccionales, es muy util para mitigar el sesgo asociado con el tiempo de los efectos invariantes e inobservables.
El primer paso es tratar nuestro modelo incluyendo las variantes relevantes, para luego decidir cual de estos modelos se ajusta mejor a nuestra base de datos (un modelo de efectos fijos o un modelo de efectos aleatorios) y analizaremos cual de ellos es el modelo.
Tratamiento previo
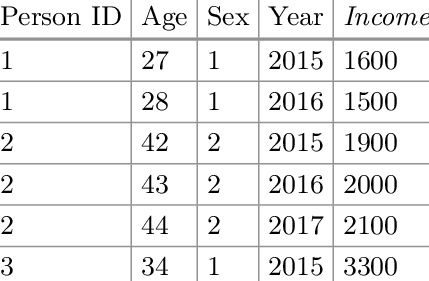
Usualmente se comienza por estimar un modelo MCO normal llamado POOLED luego el modelo de efectos fijos y el modelo de efectos aleatorios, que es lo que realizamos. Los datos del panel se usan cuando el conjunto de datos tiene informacion con respecto a una dimension de tiempo y una dimension de unidad (por ejemplo, empresa, individuo, grupo, etc. Tenemos grupos). El modelo tiene variables / regresores.
Para estimar el modelo, podemos hacer suposiciones sobre la interseccion:
Esto significa que hay una parte constante en el intercepto para todos los individuos () y una parte que cambia para cada grupo (). En un modelo de efectos fijos, es un parametro fijo y y estan correlacionados.
En un modelo de efectos aleatorios, es una variable aleatoria y y no estan correlacionados.
Cuando deberiamos usar efectos aleatorios (RE) o efectos fijos (FE)?
Usamos modelos de efectos fijos y aleatorios cuando es grande y es pequeno. Un modelo de efectos fijos es mejor si tenemos datos de todos los miembros de la poblacion. Si la poblacion es demasiado grande y tenemos una muestra entonces un modelo de efectos aleatorios es mejor y nos ahorra grados de libertad porque algunos de los parametros son variables aleatorias.
Un modelo de efectos aleatorios tiene la desventaja de suponer que el error asociado con cada unidad de seccion transversal no esta correlacionado con los otros regresores; no es muy probable que esto suceda. Si la suposicion no se cumple, el estimador de RE esta sesgado.
Efectos aleatorios vs Pooled
Se ha estimado un modelo de regresion por Minimos Cuadrados Ordinarios que es el denominado POOLED y a su vez el Modelo de efectos aleatorios con los cuales comprobaremos si el estimador de efectos aleatorios es mejor que el estimador de los minimos cuadrados ordinarios; esta decision la tomaremos en base al test de Breusch-Pagan que acompanaremos a la regresion de efectos aleatorios que el test es el siguiente.
Bajo la :
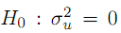 (no existen efectos aleatorios)
(no existen efectos aleatorios)
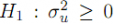
El contraste de Breusch-Pagan donde la Hipotesis nula: Varianza del error especifico a la unidad = 0 y su Estadistico de contraste asintotico: Chi-cuadrado.
Por ejemplo: Si tuvieramos el siguiente resultado se interpreta de la siguiente forma.
con valor
Con lo cual rechazamos la . Por lo que los estimadores de efectos aleatorios son mejores que un minimo cuadrado ordinario (Pooled).
Ahora lo siguiente es decidir sobre que modelo es mejor entre los efectos fijo y el de efectos aleatorios.
Efectos fijos vs efectos aleatorios - El test de Hausman
En este sentido, el test de Hausman es un contraste clasico de robustez frente a eficiencia en los estimadores. Este tipo de contrastes se plantean siempre que se quiera escoger entre dos estimadores para un mismo conjunto de parametros, uno robusto consistente tanto en la hipotesis nula como en la alternativa (cualesquiera que sean) y otro eficiente pero solo bajo la hipotesis nula .
Si, una vez calculados ambos, la diferencia observada entre los dos estimadores es escasa, se toma evidencia a favor de la hipotesis nula. La prueba de Hausman sondea la consistencia del estimador de efectos aleatorios. La hipotesis nula se puede interpretar como que estas estimaciones son consistentes, esto quiere decir, que el requisito de ortogonalidad de los errores del modelo y los regresores es satisfactorio.
La prueba se basa en una medida, , que es la "distancia" entre los efectos fijos y los estimadores de efectos aleatorios, construidos de tal manera que bajo la hipotesis nula sigue una distribucion con grados de libertad igual al numero de regresores variables en el tiempo, (esimos). Si el valor de es "grande" esto sugiere que el estimador de efectos aleatorios no es consistente y es preferible usar los estimadores del modelo de efectos fijos.
La forma del contraste de la prueba de Hausman:
- : y no estan correlacionados, entonces el modelo de efectos aleatorios, Generalized Least Squares (GLS) es consistente y eficiente y el modelo Least Squares Dummy Variables (LSDV) (FE) es consistente e ineficiente.
- : y estan correlacionados, entonces LSDV (FE) es consistente pero no eficiente, GLS (RE) no es consistente.
De igual forma presentamos los resultados para nuestros datos de ejemplo.
Contraste de Hausman -- Hipotesis nula: Los estimadores de MCG son consistentes. Estadistico de contraste asintotico:
Como podemos observar el p-valor es mayor al 5% de significacion prefijado, por lo cual el estimador de efectos aleatorios no es inconsistente, por lo tanto, usaremos el estimador de efectos aleatorios.
Aclaracion final
Estos test que realizamos nos permiten decidir la eleccion del modelo entre los efectos fijos y aleatorios, pero estos modelos no son efectivos a la hora de capturar o modelizar la presencia de Autocorrelacion y la heteroscedasticidad, para lo cual usaremos test formales para identificar que tipo de problemas estan presentes en nuestro modelo, principalmente porque hay varias maneras de modelizar y capturar los efectos en datos de panel.
Bibliografia
- Baltagi, B. H., and P. X. Wu. 1999. Unequally spaced panel data regressions with AR(1) disturbances. Econometric Theory 15: 814-823.
- Bhargava, A., L. Franzini, and W. Narendranathan. 1982. Serial correlation and the fixed effects model. Review of Economic Studies 49: 533-549.
- Greene, William H., Econometric Analysis, 2000, 4a Ed. Prentice Hall.
- Stata Longitudinal-Data/Panel-Data Reference Manual Release 11, pagina 163.
Algunos comandos utiles en R
Una referencia rapida con algunos de los comandos mas utiles en R para manipulacion de datos, operadores, funciones matematicas y estadisticas, y tests de hipotesis.
LA BRECHA SALARIAL EN BOLIVIA: LA CARRERA HACIA UNA MAYOR DESIGUALDAD
El incumplimiento de los objetivos planteados con relacion a las politicas de igualdad unido a la crisis economica aumenta extraordinariamente la brecha salarial, favoreciendo un fenomeno de exclusion.

¿Necesitas resolver algo parecido?
Modelización cuantitativa, validación de modelos y data leadership. Trabajo bajo NDA si lo pides.
Háblame de tu proyecto →