
Limpieza de una Base de Datos con R
En este ejemplo trabajaremos con cinco conjuntos de datos de ventas de propiedades que están disponibles públicamente en el sitio web de datos de ventas continuas del Departamento de Finanzas de la ciudad de Nueva York. ¡Le recomendamos que descargue los conjuntos de datos y los siga! Cada archivo contiene un año de datos de ventas de bienes raíces para uno de los cinco distritos de la ciudad de Nueva York. Trabajaremos con los siguientes archivos de Microsoft Excel:
- rollingsales_bronx.xls
- rollingsales_brooklyn.xls
- rollingsales_manhattan.xls
- rollingsales_queens.xls
- rollingsales_statenisland.xls
Los beneficios de usar las herramientas de tidyverse a menudo son evidentes en el proceso de carga y limpieza de datos. En muchos casos, el paquete tidyverse readxl limpiará algunos datos para usted, ya que los datos de Microsoft Excel se cargan en R.
Si está trabajando con datos CSV, la función del paquete tidyverse readr read_csv() es la función a usar.
El paquete de utilidades de funciones como %>% "pipes" (tuberías) hará que pasemos de una función a la siguiente. La función magrittr mutate() crear, transformar y redefinir columnas. La función dplyr select() sirve para mantener, eliminar, seleccionar o cambiar el nombre de las columnas. La función de dplyr rename() puede cambiar el nombre de las columnas. La función dplyr clean_names() nos ayudará a estandarizar la sintaxis de los nombres de las columnas, y la función as.character() de janitor puede ayudarnos a cambiar entre tipos de variable al tipo de string.
Las funciones as.numeric(), as.Date(), etc. convierten la clase de una columna. Las funciones dplyr tidyselect usan la lógica para seleccionar columnas, filter() mantiene ciertas filas, distinct() elimina filas duplicadas, rowwise() opera por/dentro de cada fila, add_row() agrega filas manualmente, arrange() ordena filas, recode() vuelve a codificar valores en una columna, case_when() vuelve a codificar valores usando criterios lógicos más complejos, replace_na(), na_if(), coalesce() funciones especiales para recodificar, age_categories() y cut() crean grupos categóricos a partir de columnas numéricas.
Bueno, menos charla y más acción. Vamos a cargar nuestra primera base de datos.
library(readxl)
brooklyn <- read_excel("rollingsales_brooklyn.xls", skip = 4)
glimpse(brooklyn)
## Rows: 29,090
## Columns: 21
## $ BOROUGH "3", "3", "3", "3", "3", "3", "3", "3"…
## $ NEIGHBORHOOD "BATH BEACH", "BATH BEACH", "BATH BEA"…
## $ `BUILDING CLASS CATEGORY` "01 ONE FAMILY DWELLINGS", "01 ONE FA"…
## $ `TAX CLASS AT PRESENT` "1", "1", "1", "1", "1", "1", "1", "1"…
## $ BLOCK 6360, 6363, 6363, 6364, 6364, 6367, 6…
## $ LOT 157, 22, 48, 74, 74, 24, 25, 65, 85, …
## $ EASEMENT NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ `BUILDING CLASS AT PRESENT` "A5", "A9", "A9", "A5", "A5", "A9", …
## $ ADDRESS "36 BAY 10TH STREET", "8645 16TH AVE"…
## $ `APARTMENT NUMBER` NA, NA, NA, NA, NA, NA, NA, NA, NA, N…
## $ `ZIP CODE` 11228, 11214, 11214, 11214, 11214, 11…
## $ `RESIDENTIAL UNITS` 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ `COMMERCIAL UNITS` 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0…
## $ `TOTAL UNITS` 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
## $ `LAND SQUARE FEET` 1547, 2058, 3142, 2492, 2492, 1571, 1…
## $ `GROSS SQUARE FEET` 1428, 1492, 3200, 972, 972, 1456, 145…
## $ `YEAR BUILT` 1930, 1930, 1999, 1950, 1950, 1935, 1…
## $ `TAX CLASS AT TIME OF SALE` "1", "1", "1", "1", "1", "1", "1", "1…
## $ `BUILDING CLASS AT TIME OF SALE` "A5", "A9", "A9", "A5", "A5", "A9", …
## $ `SALE PRICE` 0, 875000, 0, 0, 890000, 925000, 0, 0…
## $ `SALE DATE` 2022-03-18, 2022-01-07, 2022-03-14, …
La función glimpse() proporciona una forma sencilla de ver los nombres de las columnas y los tipos de datos para todas las columnas o variables en el marco de datos. Este marco de datos tiene 29,090 observaciones o registros de ventas de propiedades y hay 21 variables o columnas.
Al observar los tipos de datos para cada columna, vemos que, en general, los datos se almacenan en un formato que está listo para usar. Por ejemplo: NEIGHBORHOOD es de tipo "carácter", GROSS SQUARE FEET es de tipo "doble" (numérico), SALE PRICE también es numérico. La SALE DATE se almacena en un formato de fechas y horas del calendario.
mean(brooklyn$`SALE PRICE`)
## [1] 1290130
¡Listo para graficar!
Es útil que la FECHA DE VENTA se almacene en un formato de fechas porque esto nos permite usar una sola línea de código para hacer un histograma de ventas de propiedades por fecha:
qplot(`SALE DATE`, data = brooklyn)
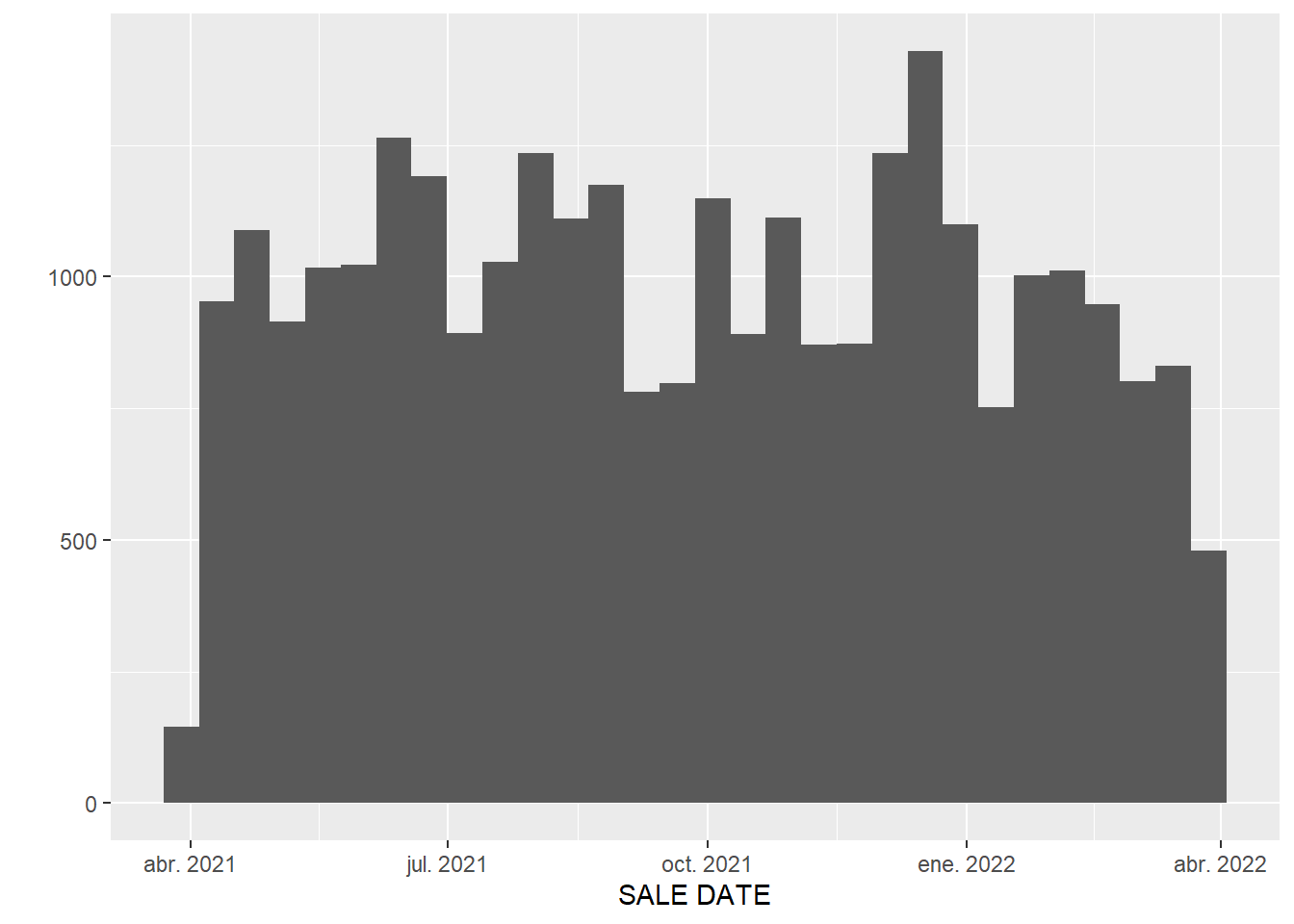
Como puede ver, con solo unas pocas líneas de código, podemos comenzar a explorar nuestros datos. Tenga en cuenta que la función qplot() utilizada para hacer el histograma es del paquete ggplot2, que es un paquete central de tidyverse.
Combinación de conjuntos de datos
Si queremos realizar un análisis de datos para los cinco condados de la ciudad de Nueva York, será útil combinar los conjuntos de datos. Hemos verificado que los nombres de las columnas son los mismos en cada uno de los cinco archivos de Excel. Entonces podemos combinar los marcos de datos con la función bind_rows() del paquete dplyr:
Fuente de los datos: https://www1.nyc.gov/site/finance/taxes/property-rolling-sales-data.page
NYC_property_sales <- bind_rows(bronx, brooklyn, manhattan, queens, staten_island)
glimpse(NYC_property_sales)
## Rows: 99,183
## Columns: 21
Este marco de datos NYC_property_sales contiene 21 variables, igual que el dataframe de Brooklyn. Esto confirma que los cinco conjuntos de datos tienen exactamente los mismos nombres de columna, por lo que podemos combinarlos sin ninguna corrección. La función bind_rows() esencialmente apiló los cinco dataframes uno encima del otro.
¡Limpie los nombres de las columnas con magrittr Magic!
Los nombres de las columnas contienen espacios, que pueden ser más difíciles de trabajar en tidyverse. Además, los nombres de las columnas contienen letras mayúsculas. Limpiemos rápidamente los nombres de las columnas usando un método práctico del paquete magrittr.
Vamos a utilizar la función de "tubería de asignación" del paquete magrittr (%<>%) para actualizar de manera eficiente todos los nombres de las variables. Las tuberías (pipes) son herramientas poderosas que permiten encadenar varias operaciones a la vez.
colnames(NYC_property_sales)
## [1] "borough" "neighborhood"
## [3] "building_class_category" "tax_class_at_present"
## [5] "block" "lot"
## [7] "easement" "building_class_at_present"
## [9] "address" "apartment_number"
## [11] "zip_code" "residential_units"
## [13] "commercial_units" "total_units"
## [15] "land_square_feet" "gross_square_feet"
## [17] "year_built" "tax_class_at_time_of_sale"
## [19] "building_class_at_time_of_sale" "sale_price"
## [21] "sale_date"
Pipes
Por lo general, cuando se trabaja con herramientas tidyverse, trabajaremos con un solo pipe (%>%) de magrittr. La canalización es una forma de vincular varios comandos. ¿Recuerda cómo podemos pensar en %<>% como "y luego actualizar"? Bueno, la tubería (%>%) se puede considerar simplemente como "y luego":
NYC_property_sales %>% glimpse()
## Rows: 99,183
## Columns: 21
## $ borough "3", "3", "3", "3", "3", "3", "3", "3"…
## $ neighborhood "BATH BEACH", "BATH BEACH", "BATH BEACH"…
Convertiremos todas las columnas que sean character a factor (cuando tenga sentido):
NYC_property_sales <- NYC_property_sales %>%
mutate(across(where(is.character), as.factor))
Los datos de las categorías de la variable building_class_at_present provienen de: https://www1.nyc.gov/assets/finance/jump/hlpbldgcode.html
Bajamos nuestra lista en un archivo CSV, y organizaremos esa tabla: cambiando los nombres de las columnas, eliminando las filas vacías, y los nombres serán todo como tipo oración y no mayúsculas.
etiquetas <- read.csv("building_codes.csv")
head(etiquetas)
## code label
## 1 A1 TWO STORIES - DETACHED SM OR MID
## 2 A2 ONE STORY - PERMANENT LIVING QUARTER
## 3 A3 LARGE SUBURBAN RESIDENCE
## 4 A4 CITY RESIDENCE ONE FAMILY
## 5 A5 ONE FAMILY ATTACHED OR SEMI-DETACHED
## 6 A6 SUMMER COTTAGE
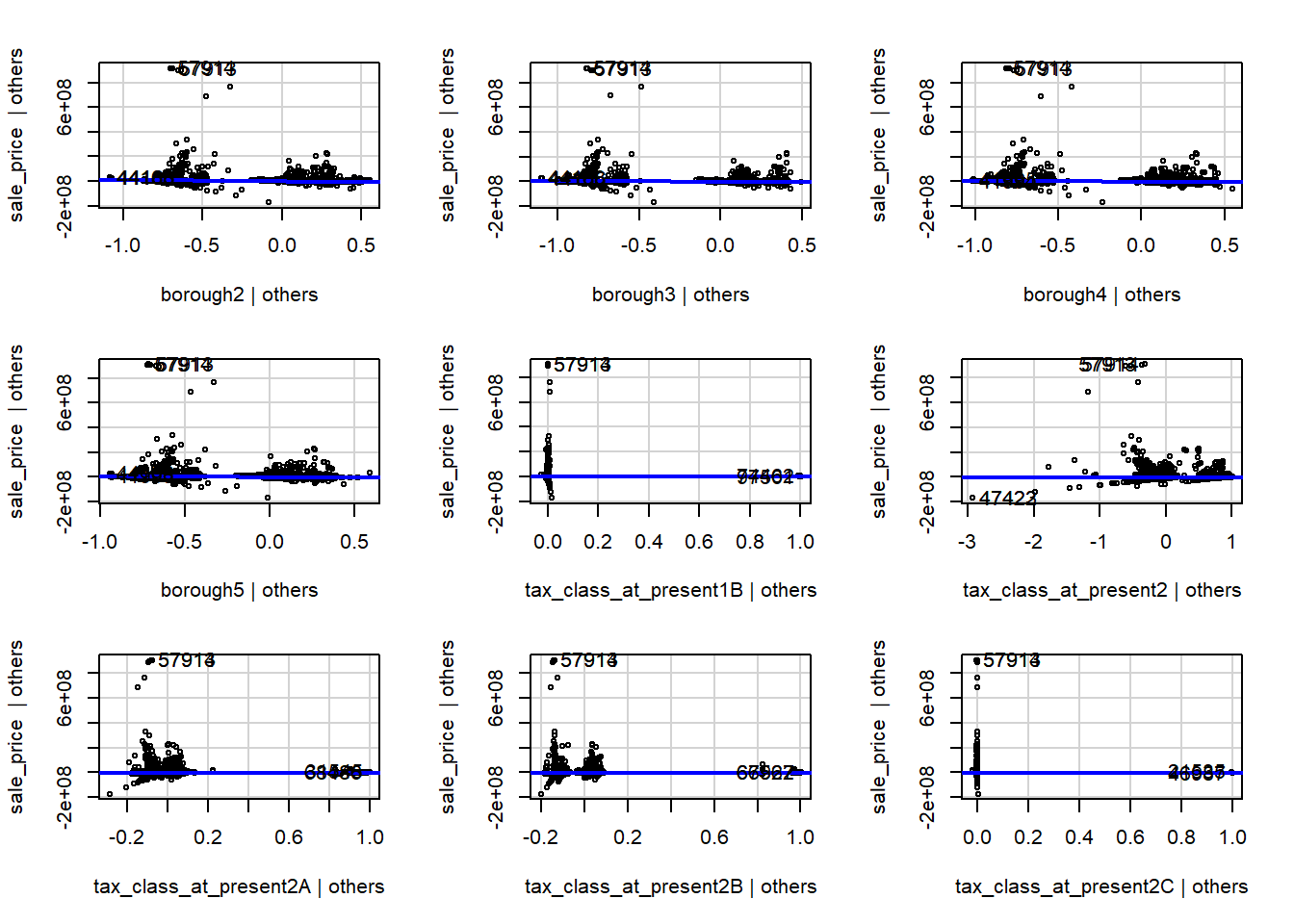
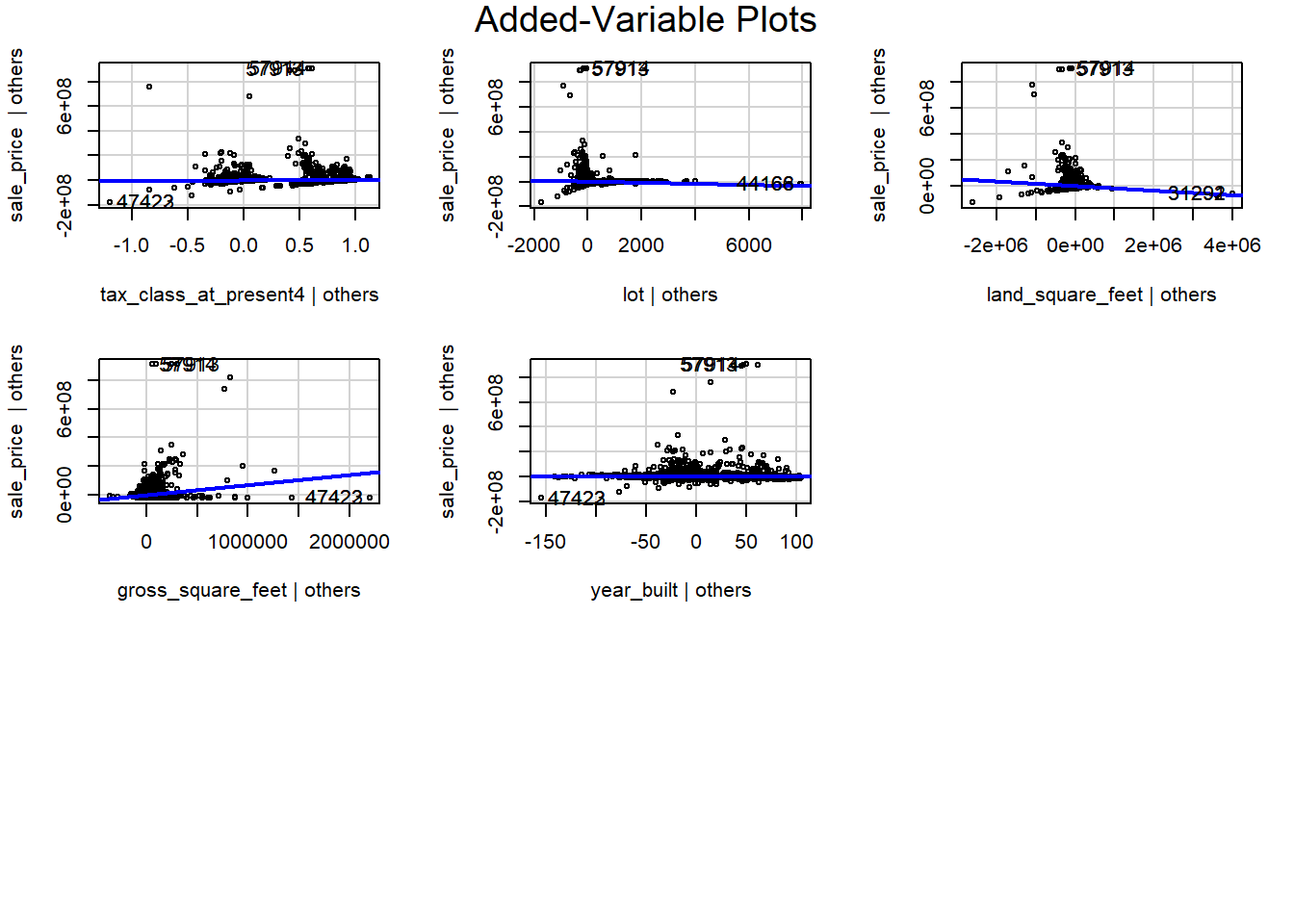
Modelo de Regresión Lineal
model1 <- lm(sale_price ~ borough + tax_class_at_present + lot +
land_square_feet + gross_square_feet + year_built,
data = NYC_property_sales)
summary(model1)
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -2.726e+06 3.755e+06 -0.726 0.467874
## borough2 -1.147e+07 3.583e+05 -31.999 < 2e-16 ***
Pruebas de Diagnóstico
Test de Breusch-Pagan (Heterocedasticidad): H0: Homocedasticidad, H1: Heterocedasticidad. El test reporta que se rechaza la H0 de Homocedasticidad. El modelo tiene heterocedasticidad.
Test de Durbin-Watson (Autocorrelación): H0: No hay autocorrelación, H1: Presencia de autocorrelación tipo AR(1). Se rechaza la H0 por lo que existe autocorrelación tipo AR(1).
Test de Jarque-Bera (Normalidad): H0: Normalidad, H1: No se distribuye como una Normal. Se rechaza la H0. Los residuos no se distribuyen como una distribución normal.
library("performance")
check_model(model1)
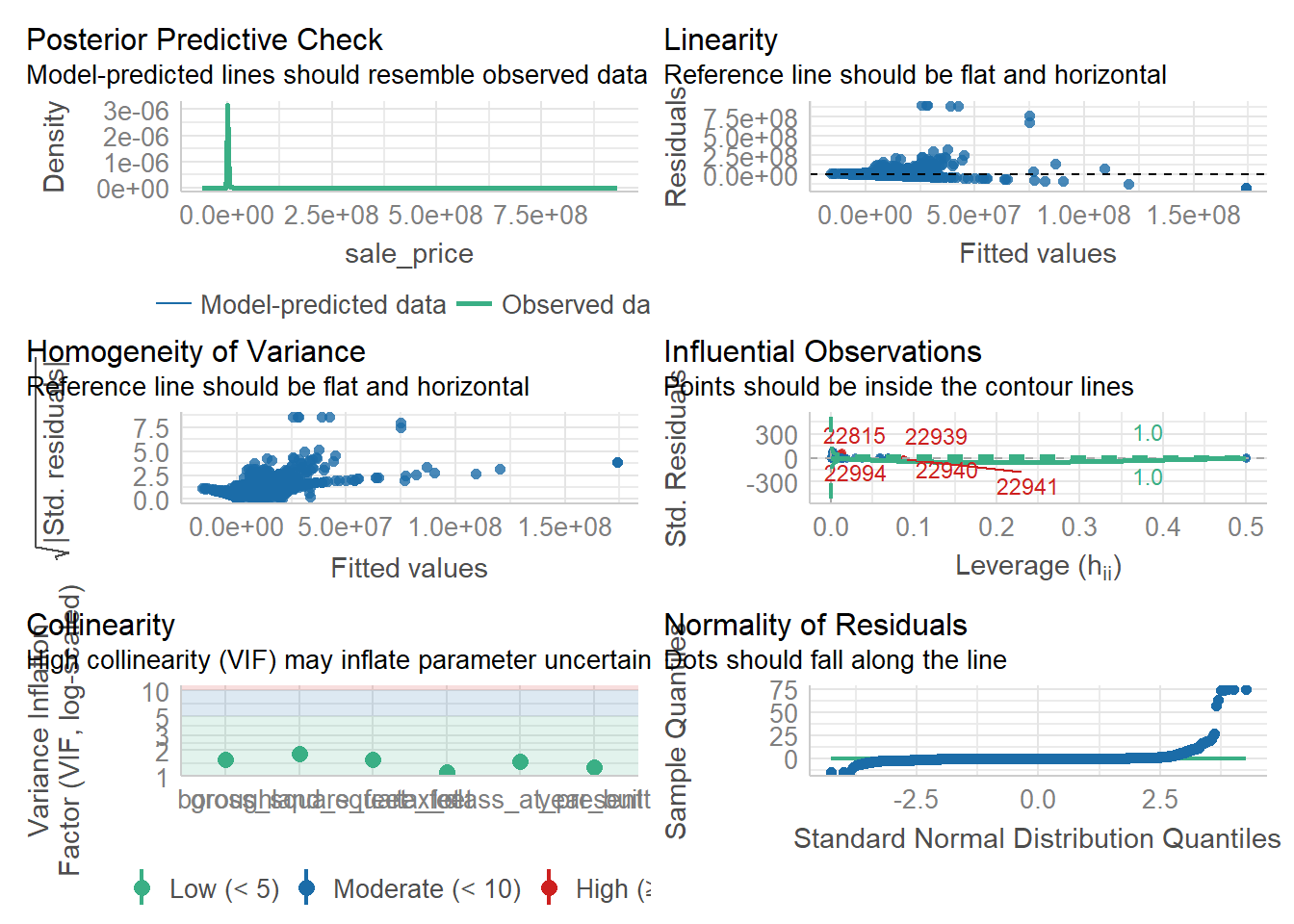
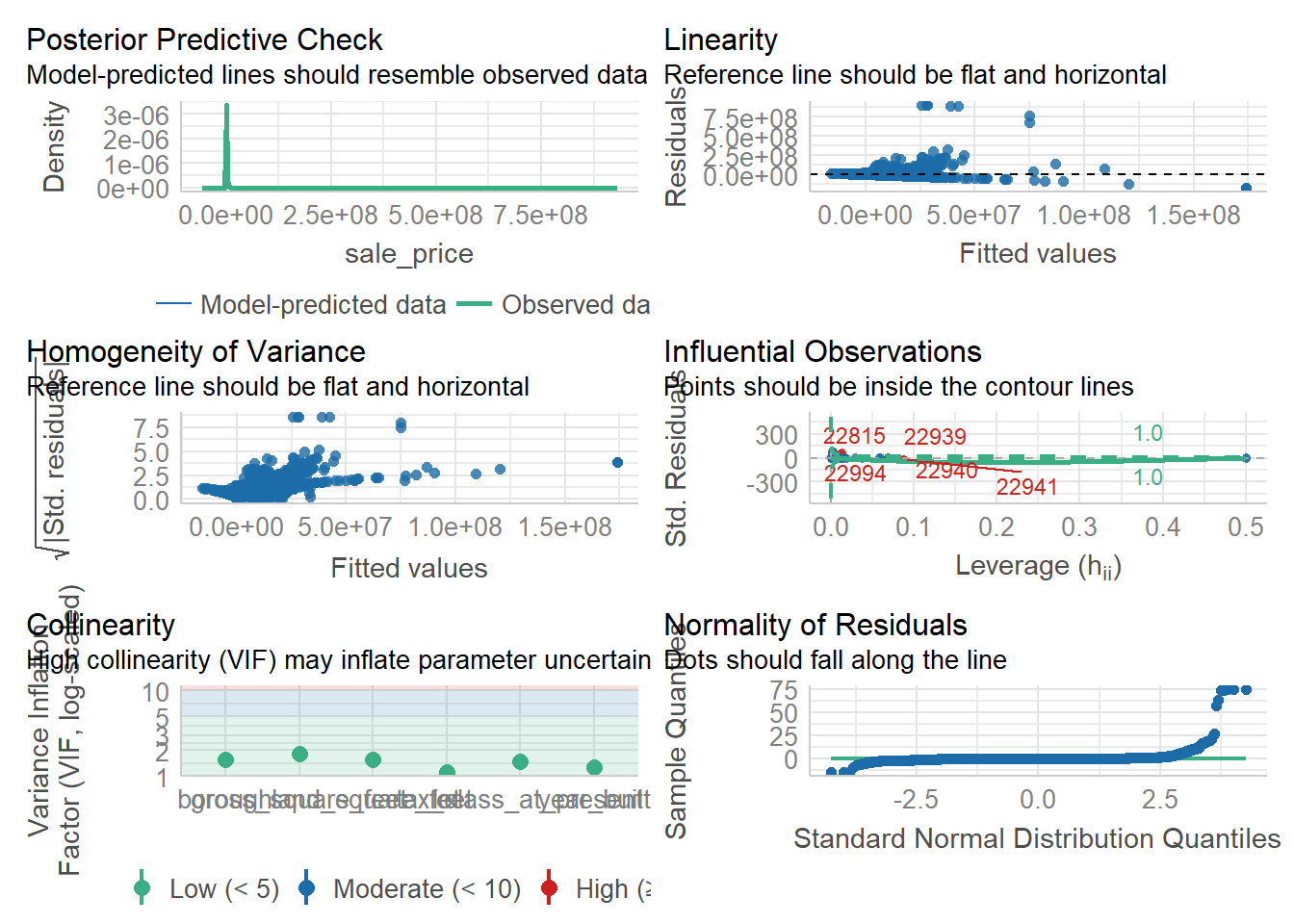
check_model(
model1,
extra_layers = list(
"collinearity" = list(scale_x_discrete(guide = guide_axis(n.dodge = 2))),
"normality" = list(theme_bw(), labs(subtitle = "Diagnóstico de normalidad"))
)
)
Rendimiento del Modelo
model_performance() calcula índices de rendimiento del modelo para modelos de regresión. Según el objeto del modelo, los índices típicos pueden ser R², AIC, BIC, RMSE, ICC o LOOIC.
model_performance(model1)
## # Indices of model performance
##
## AIC | BIC | R2 | RMSE | Sigma
## -----------------------------------------------------
## 1.794e+06 | 1.794e+06 | 0.097 | 1.214e+07 | 1.214e+07
Errores Robustos
Estimadores de matriz de covarianza tal como los introdujo Andrews (1991).
library(sandwich)
vcovHAC(model1) # errores robustos de HAC
Test de Coeficientes con Covarianza Robusta
coeftest(model1, vcov = vcovHC(model1))
## z test of coefficients:
##
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.7256e+06 5.4688e+06 -0.4984 0.6182058
## borough2 -1.1466e+07 1.4086e+06 -8.1402 3.945e-16 ***
## borough3 -1.1437e+07 1.4349e+06 -7.9702 1.584e-15 ***
## borough4 -1.1603e+07 1.4456e+06 -8.0267 1.001e-15 ***
## borough5 -1.1782e+07 1.4791e+06 -7.9654 1.647e-15 ***
## tax_class_at_present1B 5.1097e+05 2.5807e+05 1.9800 0.0477070 *
## tax_class_at_present2 -1.0022e+06 1.7516e+06 -0.5722 0.5672019
## tax_class_at_present2A -5.1883e+05 1.3402e+05 -3.8713 0.0001082 ***
## tax_class_at_present2B -1.5368e+06 5.6821e+05 -2.7046 0.0068382 **
## tax_class_at_present4 6.5412e+06 6.7912e+05 9.6319 < 2e-16 ***
Tipos de errores robustos disponibles: HC0, HC1, HC2, HC3, HC4, HC4m, HC5. Referencia: https://cran.r-project.org/web/packages/sandwich/sandwich.pdf
coeftest(model1, vcov = vcovHC(model1, type = "HC0"))
## z test of coefficients:
##
## Estimate Std. Error z value Pr(>|z|)
## (Intercept) -2.7256e+06 5.3507e+06 -0.5094 0.6104711
## borough2 -1.1466e+07 1.4053e+06 -8.1595 3.364e-16 ***
## borough3 -1.1437e+07 1.4305e+06 -7.9948 1.298e-15 ***
## borough4 -1.1603e+07 1.4418e+06 -8.0478 8.432e-16 ***
## borough5 -1.1782e+07 1.4757e+06 -7.9837 1.420e-15 ***
Referencia adicional para regresión en R: https://plotly.com/r/ml-regression/
Análisis, Tratamiento y Predicción de Stocks por Modelos ARIMA
Metodología para el análisis de series de tiempo aplicado al mercado de valores. Análisis del S&P500 mediante modelos ARIMA con R, incluyendo pruebas de estacionariedad, ACF/PACF y pronósticos.
Empirical analysis of determinants of coca leaf consumption behavior in Bolivia period 2006 – 2021
This study consolidates knowledge about the determinants of coca leaf consumption in Bolivia. Applying conditional pooled models combined with Machine Learning techniques, use the Household Surveys available at the Bolivian INE.

¿Necesitas resolver algo parecido?
Modelización cuantitativa, validación de modelos y data leadership. Trabajo bajo NDA si lo pides.
Háblame de tu proyecto →